
Training large language models requires accurate feedback signals, but traditional reinforcement learning (RL) often struggles with reward signal reliability. The quality of these signals directly influences how models learn and make decisions. However, creating robust feedback mechanisms can be complex and error prone. AWS ML Blog is strong enough to treat the story as verified, but the useful part still lies in the context and practical impact. Changes like this often look small on screen while shifting product habits and day-to-day operating workflows much faster than expected.
Featured offer
Patrick Tech Store Open the AI plans, tools, and software currently getting the push Jump straight into the store to see what Patrick Tech is pushing right now.What is happening now
Training large language models requires accurate feedback signals, but traditional reinforcement learning (RL) often struggles with reward signal reliability. AWS ML Blog form the main source layer behind the core facts in this piece. The floor is firmer here because the story is anchored by an official source, not only by second-hand reaction. In software, the upgrades worth caring about are the ones that make workflows cleaner, reduce mistakes, and remove the need for extra tools.
Where the sources line up
AWS ML Blog is strong enough to treat the story as verified, but the useful part still lies in the context and practical impact. The quality of these signals directly influences how models learn and make decisions. AWS ML Blog form the main source layer behind the core facts in this piece.
Featured offer
Patrick Tech Store Open the AI plans, tools, and software currently getting the push Jump straight into the store to see what Patrick Tech is pushing right now.The details worth keeping
However, creating robust feedback mechanisms can be complex and error prone. Changes like this often look small on screen while shifting product habits and day-to-day operating workflows much faster than expected. The people who feel the value first are often operators, editors, creators, and teams stitching multiple apps into one daily workflow. After the first update lands, the follow-up worth watching is rollout speed, stability, and whether the useful parts stay locked behind paid tiers.
Why this matters most
This story is solid enough to treat the core shift as confirmed, so the better question is how far it travels and who feels it first. Even when the core is settled, the next useful read is still the rollout speed, the real impact, and the switching cost for users or teams. Real-world training scenarios often introduce hidden biases, unintended incentives, and ambiguous success criteria that can derail the learning process, leading to models that behave unpredictably or fail to meet desired objectives.
What to watch next
The next thing to watch is rollout speed, regional limits, and whether the update really changes day-to-day habits. Patrick Tech Media will keep checking rollout speed, user reaction, and how AWS ML Blog update the next pieces. From 1 early signals, the piece keeps 1 references that are useful for locking the main details in place.
Context Worth Keeping
Training large language models requires accurate feedback signals, but traditional reinforcement learning (RL) often struggles with reward signal reliability. The quality of these signals directly influences how models learn and make decisions. However, creating robust feedback mechanisms can be complex and error prone. AWS ML Blog is strong enough to treat the story as verified, but the useful part still lies in the context and practical impact. Changes like this often look small on screen while shifting product habits and day-to-day operating workflows much faster than expected. The part worth holding onto is how a product change can ripple through the way a small team works, shares, and follows up. The floor is firmer here because the story is anchored by an official source, not only by second-hand reaction.
Source notes
- AWS ML Blog official-siteGlobal
From Patrick Tech
Contextual tools
Creator and Editor Software Stack
A practical set of tools for video, design, and multi-channel content operations.
Open Patrick Tech StoreCommunity
What did you think of this story?
Drop a reaction or leave a comment right below the article.
Related stories

Here’s why I’m optimistic about iOS 27 and Apple’s renewed focus on stability
This year, Apple is rumored to be doing a code cleanup for iOS 27 , as well as overall having a renewed focus for...

Maryland citizens slapped with $2 billion power grid upgrade bill for out-of-state...
“Without FERC action, Maryland customers face paying billions for transmission infrastructure that PJM is advancing to...
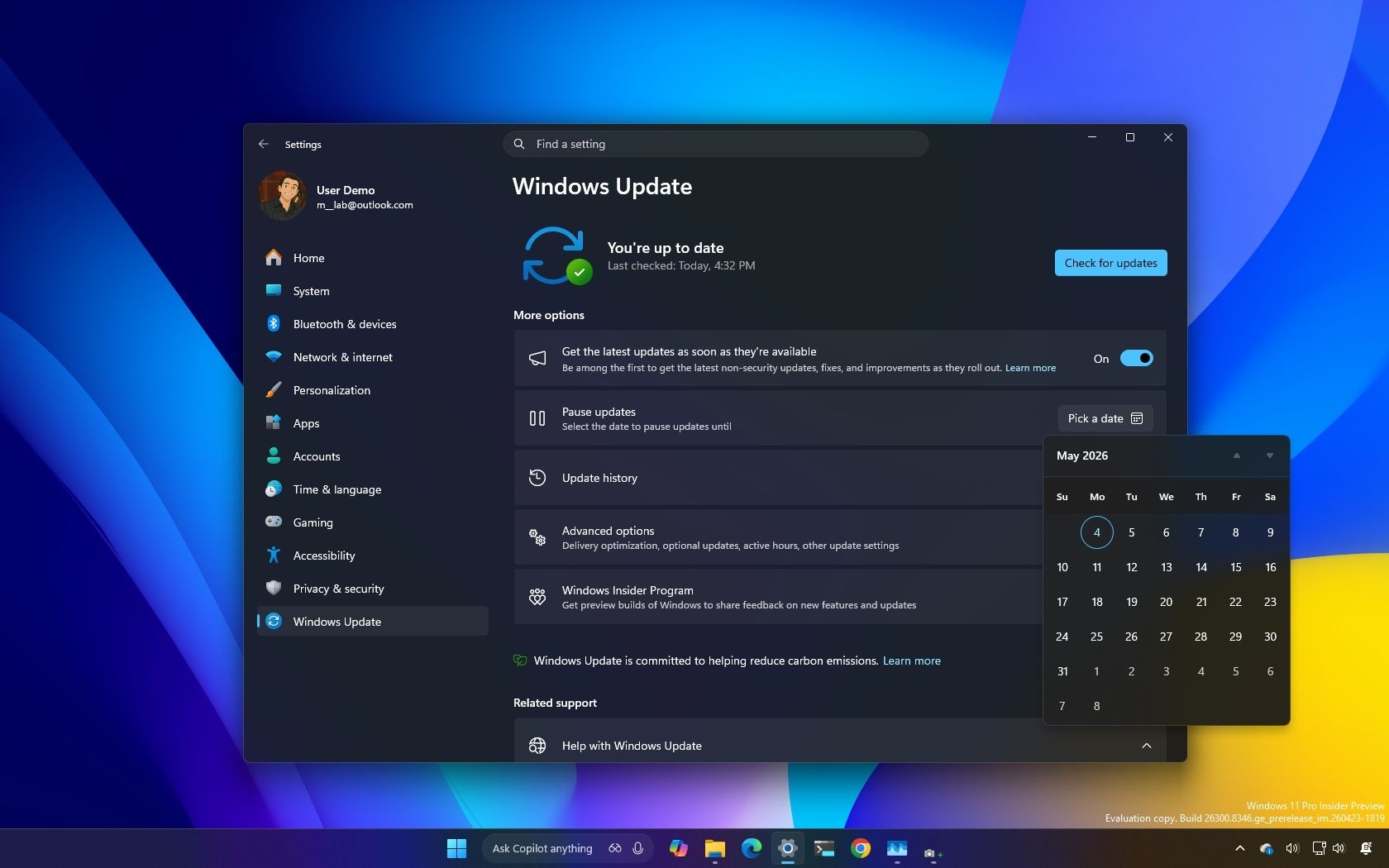
I dug into the new Windows Update rules coming to Windows 11, and these are the 5...
When you purchase through links on our site, we may earn an affiliate commission. I've gone through what's changing...
Latest comments
0No comments yet. You can start the conversation.